이번 시간에는 머신 러닝 모델이 얼마나 잘 동작하는지를 알아보는 방법을 배운다.
우리의 머신러닝 모델을 데이터로 학습을 시켰을 때 그 모델이 얼마나 성공적으로 예측을 하는지 어떻게 평가할 수 있을까? 만약 training data set으로 학습을 시킨 다음에 다시 그 training set으로 평가를 한다면 공정하지 않다.
아마 100% 완벽한 대답을 할 수 있을 것이다. 이것은 아주 나쁜 방법이다. 시험을 볼 때 답을 이미 외워놓는 것과 같은 것이다. 그래서 보통은 전체 데이터셋 중에서 70%를 training data set으로, 나머지 30%를 testing data set으로 설정한다. testing dataset은 숨겨놓고 절대로 학습할 때 보지 않도록 한다. 훈련이 완벽하게 끝났다고 했을 때 이 testing set으로 성능을 평가한다.

보통은 training set과 testing set을 나누는 것이 일반적이다. learning rate(alpha), regularization(lamda)의 값을 더 잘 선택하기 위해서 training set 중에서 일부를 validation dataset으로 설정해놓는다. 이 경우에는 training set으로 모델을 학습을 시킨 다음, validation set으로 alpha나 lamda의 값을 변경시켜가면서 결과를 확인하여 어떤 값이 가장 적합할지 튜닝을 시킨다. 완벽하게 tuning이 완성되었다고 하면 testing set으로 성능을 확인한다.
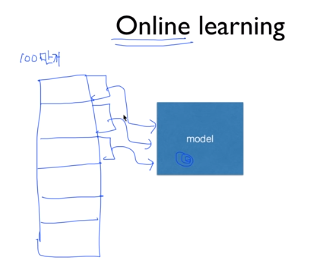
dataset이 너무 많은 경우에 메인메모리에 전부 올려서 학습을 하지 못하는 경우도 있다. 이럴 때는 online learning이라는 방법을 사용한다. 예를 들어, training set이 100만개가 있다면 10만개씩 나눠서 모델에 차례대로 학습을 시킨다. 이 때, 이 모델은 이전의 부분 데이터셋에 대해 학습된 결과가 남아있어야한다. 이것은 매우 좋은 모델이라고 인정받는데 왜냐하면 학습을 시키는 도중 새로운 데이터가 추가가 되더라도 모델에 누적이 될 수 있기 때문이다.

유명한 MINIST Dataset을 보도록 하겠다. 사람들이 손으로 쓰는 숫자를 컴퓨터가 인식하도록 학습하는 것이다.
미국 우체국에서 사람들이 손으로 적은 우편번호를 컴퓨터가 자동으로 인식해서 편지를 분류하도록 하기 위해서 만들어졌다. training set과 test set으로 나뉘어져 있다.
우리가 가자고 있는 모델이 얼마나 정확한 결과를 내놓는지 알기 위해서 accuracy를 측정한다.
최근 이미지를 인식하는 모델은 95~99% 정도로 아주 잘 되고 있다고 한다.
실제로 어떻게 인식하는지는 lab 시간에 알아볼 수 있다.
다음 시간에는 Deep Neural Nets에 대해 배우도록 하겠다.
'AI > [DLBasic]모두의 딥러닝(딥러닝의 기본)' 카테고리의 다른 글
| [DLBasic] 8-2. Back-propagation과 Deep의 출현 (0) | 2020.01.16 |
|---|---|
| [DLBasic] 8-1. 딥러닝의 기본 개념 : 시작과 XOR 문제 (0) | 2020.01.16 |
| [DLBasic] 7-1. Application & Tips: Learning rate, data preprocessing, overfitting (0) | 2020.01.16 |
| [DLBasic] 6-2. Softmax Classifier's cost function (0) | 2020.01.16 |
| [DLBasic] 6-1. Softmax Classification : Multinomial Classification (0) | 2020.01.16 |



