저번 시간에는 간단하게 CNN의 개념을 알아보았다. 이번 시간에는 max pooling 등을 알아보도록 하겠다.
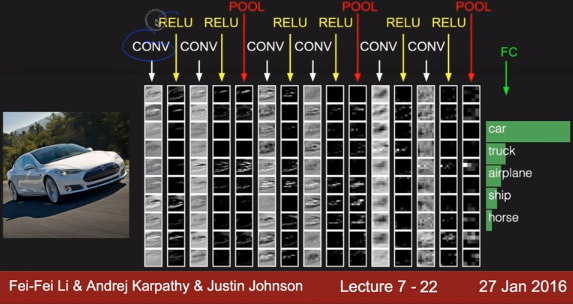
저번 시간에도 살펴보았듯이 CNN에서는 중간중간에 pooling이라는 단계가 있었다.

pooling은 간단하게 샘플링이라고 볼 수 있다. 저번 시간에 배웠듯이 한 개의 convolutional layer의 깊이는 몇 개의 필터를 사용하는지에 따라 달라졌었고, 여기에서 한 개의 layer만 뽑아내서 작은 사이즈로 축소하는 것이 pooling layer이다.
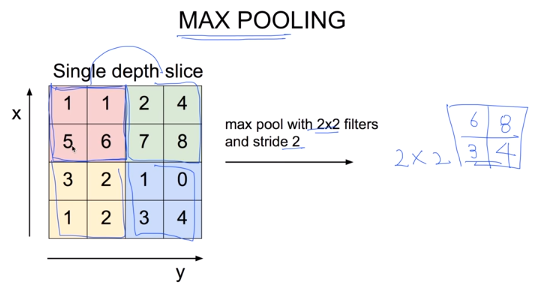
위의 예시를 보자. stride 2이므로 2칸씩 이동하고, 2 x 2 필터이므로 2 x 2의 결과가 나올 것이다. 각각의 필터에서 가장 큰 값을 뽑아낸다면 맨 오른쪽과 같은 결과가 나올 것이다. 필터와 stride를 어떻게 정하느냐에 따라 다음 결과의 크기가 정해진다.
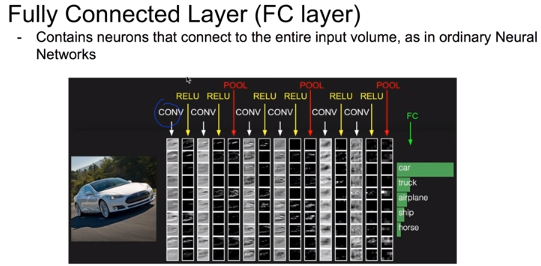
지금까지 Convolutional Neural Network을 구헝하는 convolutional layer, ReLU, Pooling에 대해서 알아보았다. 이것들을 어떤 순서로 구성하는지는 모델 구성 프로그래머에게 달려있다.
ConvNetJS demo : training on CIFAR-10
http://cs.stanford.edu/people/karpathy/convnetjs/demo/cifar10.html
이것이 어떻게 동작하는지 위의 사이트에서 살펴볼 수 있다.
다음 시간에는 ConvNet의 활용 예에 대해 살펴보겠다.
'AI > [DLBasic]모두의 딥러닝(딥러닝의 기본)' 카테고리의 다른 글
| [DLBasic] 11 - 3. CNN case study (0) | 2020.01.20 |
|---|---|
| [DLBasic] 11 -1 . CNN introduction (0) | 2020.01.20 |
| [DLBasic] 10 - 4. NN LEGO Play (0) | 2020.01.20 |
| [DLBasic] 10 - 3. NN dropout and model ensemble (0) | 2020.01.20 |
| [DLBasic] 10 -2 . Initialize weights in a smart way (0) | 2020.01.20 |



