이번 시간에는 numpy dimensional array의 약자인 ndarray에 대해 알아보도록 하겠다.

저번 시간에도 설명했듯이 numpy를 사용하기 전에는 import해야하고 통상적으로 np로 호출한다.

numpy에서 array를 생성할 때는 위와 같은 방법을 사용한다. np.array를 쓰고 데이터 타입도 지정한다.
저번 시간에 설명했듯이 float, int, str 등 한 가지 데이터 타입만 선택해서 생성할 수 있다. list라기보다 python이 dynamic typing을 지원해서 여러 데이터 타입을 하나의 배열에 넣을 수 있는데 numpy array는 이를 허용하지 않는다. list와 달리 여러 개의 데이터 타입이 들어가진 않지만 한 가지 데이터 타입만 넣음으로써 속도가 빠르고, c로 array를 형성하게 된다.

사용 예시는 위와 같다. 이 경우에서는 type은 64비트짜리 float이다. 하나의 값이 8 바이트인 것이다.
타입은 np.float16, np.int32, np.str 등 다양한 옵션이 있다.
dtype이라는 속성을 사용하면 ndarray의 데이터 타입을 알 수 있다.

numpy와 list의 차이는 numpy는 데이터가 붙어서 하나의 메모리 영역을 차지한다. 그에 비해서 python의 list는
어떤 값의 주소값을 리스트가 저장하는 것이다. 그래서 for loop으로 list의 각 값을 돌린다면 각각의 주소값에 따라서 방문해서 값을 가져와야하기 때문에 시간이 오래 걸린다고 한다.

데이터 타입이 float32이니 하나의 값이 차지하는 공간이 32비트, 4바이트이다.

데이터의 타입을 보려면 dtype을 사용하고, shape으로는 차원 구성을 볼 수 있다.
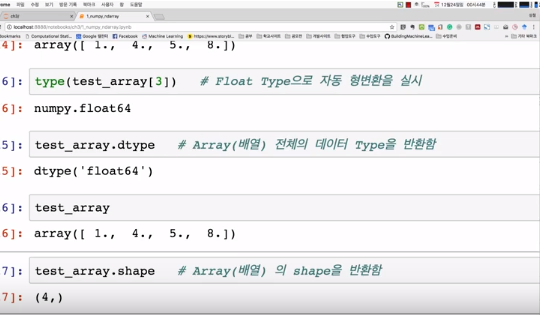
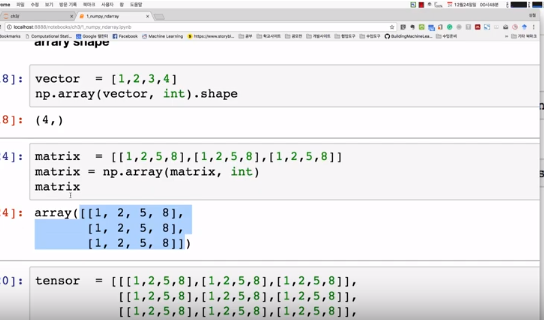
위에서 보면 shape가 (4, )라고 나왔는데 이것은 1차원일 때이다. 이것은 vector이고, 안의 element가 4개라는 뜻이다. 만약 이차원이면 (4, 4), 삼차원이면 (4, 3, 4) 이런 식일 것이다.

vector, matrix, tensor에 대한 개념을 알아보겠다. vector는 1차원, matrix는 2차원, tensor는 3차원 이상을 나타낸다.


4개의 matrix가 있고, 각각이 3개의 행과 4개의 열을 가진 matrix라는 것이다.
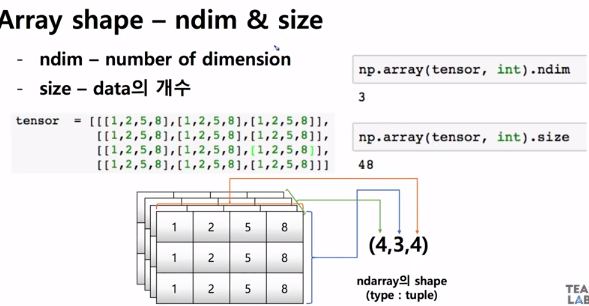
ndim은 차원을 나타내고, size는 전체 값 개수를 나타낸다.

이 상황에서 matrix는 4 x 3인 12개, tensor는 4 x 3 x 4인 48개가 있을 것이다.

다음은 array의 dtype에 대해서 알아보겠다. numpy dimension array는 각각의 원소의 데이터 타입을 정할 수 있따.
각 원소가 차지하는 메모리의 크기를 결정할 수 있는 것이다. 이것이 중요한 이유는 이미지를 다루거나 회사에서 쓸 때는 매우 큰 크기의 데이터를 다룰 때에는 이렇게 데이터 타입을 어떻게 사용하는지가 중요할 수 있다.

numpy의 데이터 타입은 c의 데이터와 호환이 된다.

위와 같이 nbytes로 몇 바이트를 사용하고 있는지 알 수 있다.
다음 시간에는 numpy에서 shape를 다루는 법을 알아보도록 하겠다.
'AI > [TEAMLAB]Numpy 사용법' 카테고리의 다른 글
| [TEAMLAB] 3 - 6. numpy - operation functions (0) | 2020.01.20 |
|---|---|
| [TEAMLAB] 3 - 5. Create Function (0) | 2020.01.20 |
| [TEAMLAB] 3 - 4. Indexing & Slicing (0) | 2020.01.20 |
| [TEAMLAB] 3 -3 . numpy - handling shape (0) | 2020.01.20 |
| [TEAMLAB] 3-1. Numpy Overview (0) | 2020.01.16 |



