이번 시간에는 array를 만드는 함수에 대해서 알아보도록 하겠다.

처음에 배울 것은 arange로 array를 지정해놓은 range에 따라서 만드는 것이다.
list의 경우에서는 list(range(10))의 형태로 0~9의 list를 만들었었다.
numpy의 경우에도 마찬가지로 np.arange(10)의 형태로 0~9까지의 vector를 만들 수 있다.
list처럼 numpy도 시작, 끝, step으로 범위를 지정할 수 있고, list와 달리 floating 포인트로 step을 표현할 수 있다는 것이
특징이다.

numpy 배열을 tolist 함수를 통해서 list로 표현할 수도 있다.

zeros는 0으로 가득찬 ndarray를 만드는 것인데 shape라고 키워드를 써도 되도 안 써도 된다. 데이터 타입도 지정할 수 있다.

ones도 비슷하게 1로 가득찬 ndarray를 만드는 것이다.

empty는 shape만 주어지고 비어있는 ndarray가 생성된다. 초기화가 되지 않기 때문에 이상한 값들이 들어있을 수 있다. 잘 쓸 일은 없을 것이라고 한다.
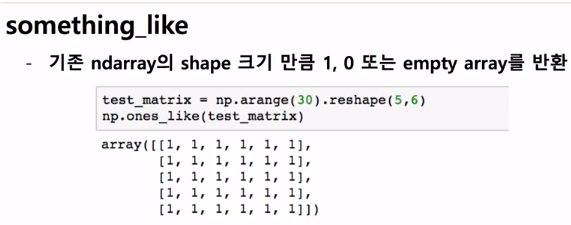
something_like는 위에서 설명했던 ones, zeros 등이 들어갈 수 있다.
실제로 코드로 사용할 때에는 shift + tab을 누르면 위와 같이 함수의 argument들을 알 수 있다.


empty는 메모리 특정 영역만 잡고 초기화가 안 되어있기 때문에 ctrl+enter 누를 때마다 값이 계속 바뀐다.

ones_like는 기존의 matrix의 원소들만 1로 다 만들어준다. 기존의 matrix와 크기, 모양은 같다.
zeros_like도 0으로 채우는 것뿐 똑같다.

다음으로는 선형대수의 matrix에서 나오는 여러 개념들을 알아보도록 하겠다. n x n 형태의 단위행렬을 만들어준다.
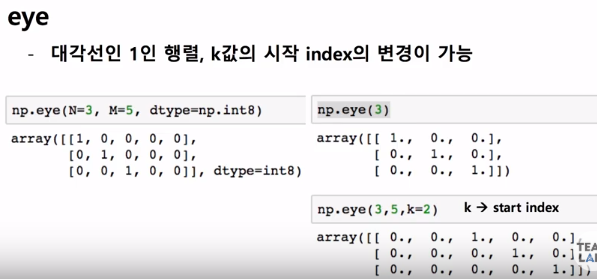
eye는 대각선이 1인 행렬인데 n과 m의 값을 지정해줄 수 있고, n은 행, m은 열에 해당한다. 만약 정방행렬이라면 단위행렬과 같을 것이다. row, column이 0인 값부터 시작하는데 k의 값을 지정하여 시작하는 값을 변화시킬 수 있다.

diag 함수는 대각 행렬의 값만 뽑아서 가져온다. eye와 마찬가지로 k로 시작 위치를 설정할 수 있다.

random sampling은 분표에 따른 값들을 가져올 수 있다. uniform이라고 표현되는 균등분포는 첫번째 argument에 최저값, 최고값, 데이터의 개수를 넘긴다. 이 경우에는 0에서 1까지 10개를 가져와서 2 x 5 모양으로 만들어준다.
normal은 정규분포이고 이 경우에는 평균이 0이고 정규분포가 1인 것에서 10개를 뽑아오라는 것을 의미한다.
이것은 딥러닝에서 굉장히 많이 쓰일 것이니 꼭 기억하자.

위와 같이 diag를 사용하면
0 1 2
3 4 5
6 7 8
이라는 matrix에서 대각선 값인 0, 4, 8만 뽑아올 수 있다.
만약 k가 1이면 1, 5를 가져왔을 것이다.
다음 시간에는 operation functions에 대해 배우도록 하겠다
'AI > [TEAMLAB]Numpy 사용법' 카테고리의 다른 글
| [TEAMLAB] 3 - 7. numpy - array opeations (0) | 2020.01.20 |
|---|---|
| [TEAMLAB] 3 - 6. numpy - operation functions (0) | 2020.01.20 |
| [TEAMLAB] 3 - 4. Indexing & Slicing (0) | 2020.01.20 |
| [TEAMLAB] 3 -3 . numpy - handling shape (0) | 2020.01.20 |
| [TEAMLAB] 3 -2 . numpy -ndarray (0) | 2020.01.20 |



