저번 시간에는 machine learning에 대해 간단하게 배웠고 어떻게 작동하는지 알아보았다.

이미 답이 있는 labeled training dataset으로 모델을 일단 훈련시키고 나면 test dataset으로 우리의 모델을 검증한다. 이런 종류의 머신러닝을 지도학습(Supervised Learning)이라고 하고, 이것은 답이 있는 데이터로 우리의 모델을 훈련시키고 이끌기 때문에 그렇다.

우리의 모델을 디자인하기 위해서 가장 먼저 할 것은 입력 데이터과 출력 데이터의 관계를 파악하는 것이다.
위의 예시 데이터의 경우에는 입력과 출력이 선형(linear)의 관계를 가지고 있어서 비례한다.
선형 모델는 매우 쉽고 간단하지만 머신러닝을 처음 시작하기에 딱 적합하다.
x라는 입력값을 받으면 선형 모델로 예측한 뒤 예측값 y hat(y 위에 ^가 있는 모양)을 얻는 것이다.
y hat = x * w + b의 형태를 만족한다. 그런데 이번 시간에는 처음 머신러닝을 배우는 사람들을 위하여 편향인 b를 제거하여 더 간단하게 학습할 수 있도록 한다.

위의 그림의 오른쪽 선형 데이터가 Linear Regression의 가장 간단한 예이다. 아까 말했듯이 편향 b는 편의를 위해서 잠시 제거를 했으므로 우리의 예측 식은 y hat = x * w의 형태가 되는데, x는 이미 입력값으로 주어졌고, 가중치 w를 랜덤으로 결정한 뒤 다른 w 값들로 실험해보면서 가장 좋은 결과를 내는 가중치를 선택한다.

loss라고도 불리는 error은 실제 값인 y와 예측값인 y hat의 차의 제곱이다. 가중치 w는 랜덤 값이고 그에 따라 예측값 y hat은 변화할 것이다. 위의 예는 w = 3일 때의 loss이고, 이렇게 구한 loss들을 더해서 개수로 나눈 평균을 구한다.

이번에는 w = 4일 때의 결과이다.


위의 w = 2일 때의 값은 매우 의미가 있는데, loss가 모두 0이 나와서 가장 정확한 예측값이기 때문이다.
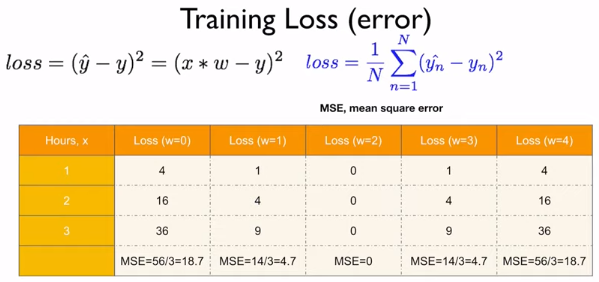
여기서 loss를 구한 방식은 모든 점에서의 예측값과 실제값의 차를 제곱해서 그 개수만큼 나눈, 마치 평균을 구하는 것과 같았다. 이 방법을 MSE(Mean Square Error)라고 한다.

각각의 점들을 그래프 위에 찍은 뒤 연결해본다면 위와 같은 결과를 얻을 수 있다.
이 그래프를 통해서 가장 작은 값을 갖는 weight값을 결정할 수 있다.


우리는 y hat과 loss 값을 pytorch로 위와 같이 구할 수 있다.
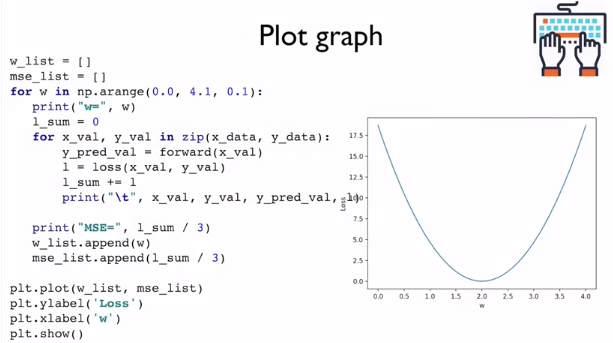
위와 같이 그래프의 형태로도 출력할 수 있다.

위의 코드가 이전의 모든 코드들을 모아놓은 전체 프로그램이다.

지금 한 단계를 자동으로 컴퓨터가 하게 할 다음 시간으로 넘어가기 전에 위의 문제들을 한 번 생각해보자.
다음 시간에는 Gradient Descent를 알아보도록 하겠다.
'AI > PyTorchZeroToAll by Sung Kim' 카테고리의 다른 글
| [PyTorchZeroToAll] 6. Logistic Regression (0) | 2020.01.23 |
|---|---|
| [PyTorchZeroToAll] 5. Linear Regression in the PyTorch way (0) | 2020.01.22 |
| [PyTorchToAll] 4. Back-propagation (0) | 2020.01.22 |
| [PyTorchZeroToAll] 3. Gradient Descent (0) | 2020.01.21 |
| [PyTorchZeroToAll] 1. Overview (0) | 2020.01.20 |



