저번 시간에는 linear regression을 pytorch로 구현해보았다. 이번 시간에는 logistic regression을 pytorch로 구현해보도록 하겠다.

linear regression의 예에서는 실수를 입력으로 받고, 실수를 출력으로 내보냈다. 그런데 실생활에서는 0 or 1으로만 나뉘는 경우도 많이 있다. n 시간 공부했을 때 시험을 통과할지 떨어질지, 이 GPA, GRE 성적으로 홍콩과기대의 박사 과정에 통과할 수 있을지 아닐지, 일본과의 축구 경기에서 이길지 질지, 마음에 드는 이성에게 프로포즈할지 아닐지 이런 예들이 해당된다.

그렇다면 이런 0 또는 1의 결과는 어떤 입력과 출력을 우리의 모델에 주어야할까?
위의 식에 해당하는 시그모이드 함수를 사용한다. 입력이 커질수록 출력이 1에 가까워지고, 입력이 작을수록 출력이 0에 가까워진다. 이렇게 0과 1 사이의 실수 결과가 나온다면 특정한 임계치를 정하고 그 이상이면 1로 판단하고, 그것보다 작으면 0으로 판단한다. 일반적인 임계치는 0.5를 사용하고, 우리가 예측한 y hat이 0.5가 넘으면 1이 되는 것이다.

binary classification의 경우에는 sigmoid 함수를 사용하기 때문에 기존의 손실함수가 제대로 작동하지 않는다. 그렇기 때문에 cross entropy loss 함수를 사용하도록 할 것이다.
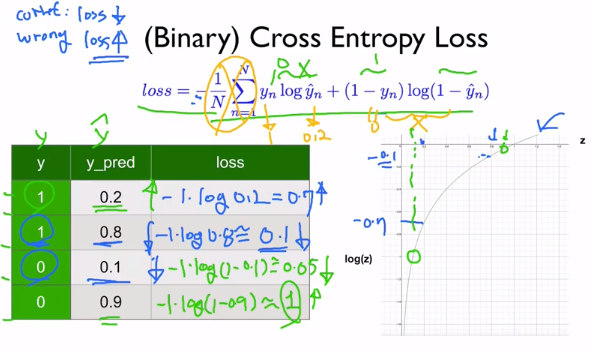
이전에도 그러했듯이, 예측을 잘 했다면 loss 함수의 결과가 작을 것이고, 예측을 잘못 했다면 loss 함수의 결과가 클 것이고, 이럴 때 벌을 주어서 모델을 조정한다.
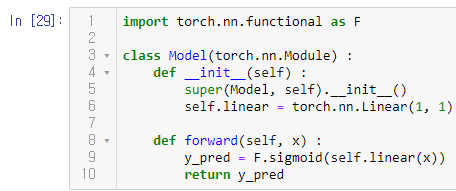
sigmoid 함수는 torch.nn.functional.sigmoid로 미리 정의되어있으므로 간편하게 사용할 수 있다.

sigmoid 함수에 맞게 logistic regression에서는 MSE loss function이 아니라 위의 방법을 사용한다.
BCE는 Binary CrossEntropy를 뜻한다.



우리의 예상대로, 훈련의 결과는 위와 같이 점점 진행될수록 손실 함수의 값이 줄어든다.
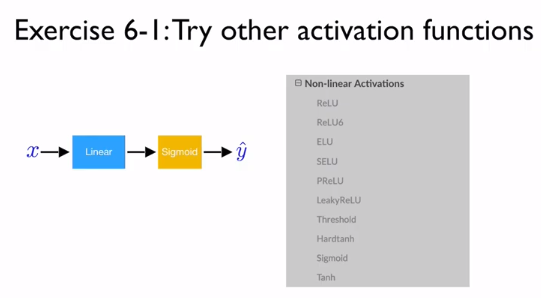
이번에는 활성 함수(activation function)으로 시그모이드 함수를 사용했다. 여러 활성 함수들이 있으니 활용해서 예측을 해보자.
다음 시간에는 logistic regression이나 neural network를 어떻게 적용하는지를 알아보겠다.
'AI > PyTorchZeroToAll by Sung Kim' 카테고리의 다른 글
| [PyTorchZeroToAll] 8. PyTorch DataLoader (0) | 2020.01.27 |
|---|---|
| [PyTorchZeroToAll] 7. Wide and Deep (0) | 2020.01.27 |
| [PyTorchZeroToAll] 5. Linear Regression in the PyTorch way (0) | 2020.01.22 |
| [PyTorchToAll] 4. Back-propagation (0) | 2020.01.22 |
| [PyTorchZeroToAll] 3. Gradient Descent (0) | 2020.01.21 |



