이번 시간에는 우리가 사용할 큰 데이터를 더 빠르게 로드하는 법에 대해 알아보도록 하겠다.

저번 시간에는 위와 같이 모든 데이터를 로드한 뒤에 각각을 ,로 구분해서 x_data와 y_data로 하나하나 구분했다.
훈련 단계에서도 모든 데이터들을 모델에 하나하나 모두 넣어서 예측값을 얻었다. 위의 예시에는 데이터가 700여개였기 때문에 크기가 작아서 모든 데이터를 하나하나 처리하기 어렵지 않았다. 하지만 만약 데이터의 크기가 매우 커지면 이런 식으로 하나하나 처리하기 어려워질 것이고 효율적이지 않다.
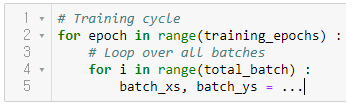
그래서 우리는 batch라는, 데이터를 일정한 크기로 묶어서 처리할 것이다.

epoch, batch의 크기, 반복 횟수에 대한 정의는 위와 같다.
epoch는 전체 데이터를 다루지만, batch는 일정한 크기로 나눠서 생각한다.
예를 들어, 만약 전체 데이터가 1000개이고 배치 크기가 500이라면 반복은 2번 하는 것이다.
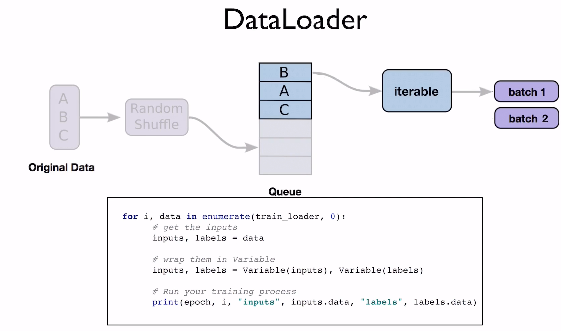
이렇게 batch를 설정해서 나누는 작업을 우리가 직접 구현할 수도 있지만, pytorch에는 data loader라는 것이 이미 구현되어있어서 우리는 간편하게 사용할 수 있다.





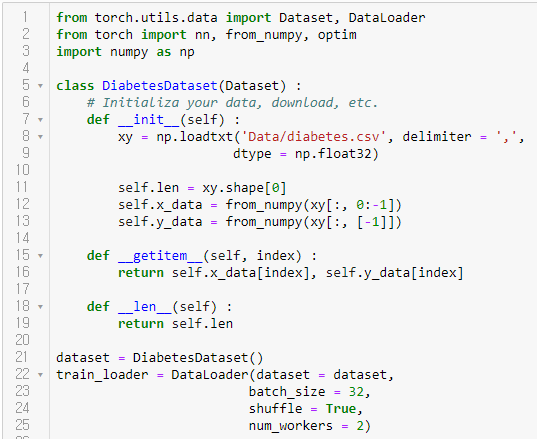
저번 시간에 사용했던 똑같은 비만 데이터가 위와 같이 dataloader로 간편하게 사용되는 것을 볼 수 있다.
DataLoader에서 사용되는 파라미터들 중 dataset은 어떤 데이터를 사용할 것인지 지정하고, batch_size에는 batch의 크기를 지정하고, shuffle에 True를 지정하면 우리에게 주어진 데이터를 섞어서 치우치지 않은 모델을 만들 수 있다.
그리고 이 Loader를 여러 프로세스에서 사용한다면 num_workers로 수를 지정할 수 있다.
만약 비만 데이터를 여러 군데에서 사용한다면, class DiabetesDataset을 별도의 파일에 구현해서 필요할 때마다 inport하면 코드의 재사용성이 높아지고 매번 상세한 코드를 알 필요가 없어서 더 효율적으로 코드를 짤 수 있다.

이번에 배운 DataLoader 이외에도 위와 같은 dataset loader들도 가능하다.

MNIST 데이터에 적용하면 위와 같을 것이다.
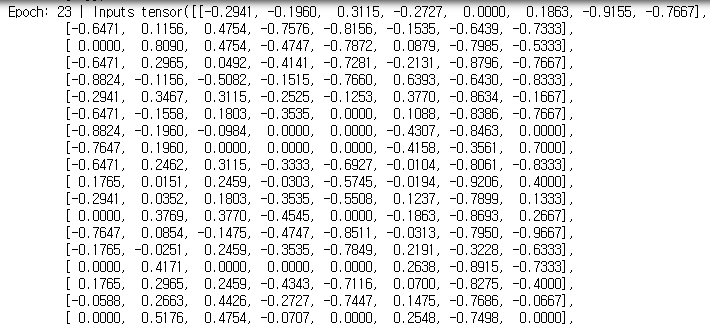
batch size로 train하는 train_loader로 for loop를 돌면서 training시킨다.

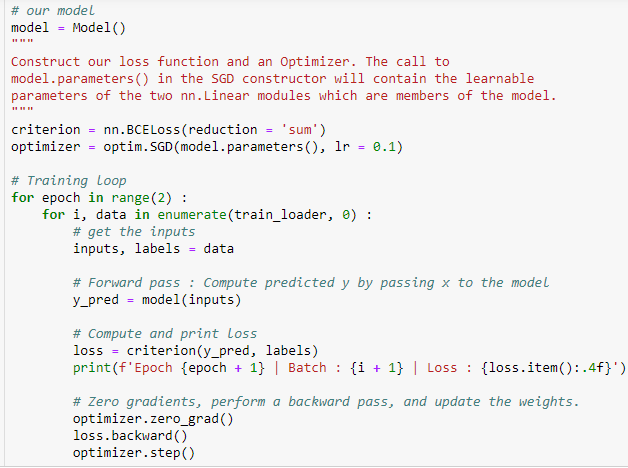
dataset load를 logistic regression으로 하면 위와 같다.
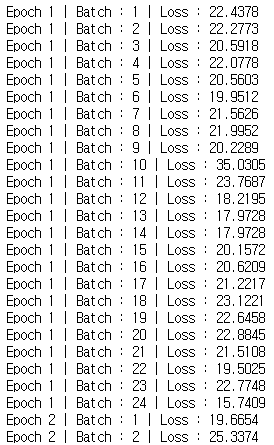
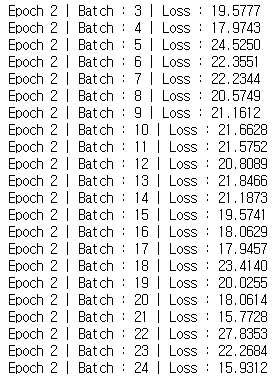
위와 같은 결과가 나온다. batch 단위로 해도 loss function의 결과가 점점 줄어드는 것을 볼 수 있다.

위의 데이터로 DataLoader 사용하는 법을 연습해보자.
다음 시간에는 softmax classifier에 대해 알아보도록 하겠다.
'AI > PyTorchZeroToAll by Sung Kim' 카테고리의 다른 글
| [PyTorchZeroToAll] 10. CNN (0) | 2020.01.28 |
|---|---|
| [PyTorchZeroToAll] 9. Softmax Classifier (0) | 2020.01.27 |
| [PyTorchZeroToAll] 7. Wide and Deep (0) | 2020.01.27 |
| [PyTorchZeroToAll] 6. Logistic Regression (0) | 2020.01.23 |
| [PyTorchZeroToAll] 5. Linear Regression in the PyTorch way (0) | 2020.01.22 |



