이번 시간에는 신경망 구조 중 가장 유명한 CNN에 대해 알아보도록 하겠다.

이미지를 입력으로 받고, convolution을 해서 feature map들을 얻는다. subsampling을 한 뒤 linear layer로 이어져서 classification을 수행한다.

convolution이 무엇인지 알아보자. 만약 사진 한 장이 있다면 그것은 가로폭(width), 세로폭(height), 그리고 색을 나타내는 R(빨강), G(초록), B(파랑)의 수치가 있을 것이다. softmax 함수를 적용하는 경우에는 모든 픽셀 정보를 입력으로 넣을 것이다. 그런데 convolution의 경우에는 이미지의 매우 작은 부분, 패치(patch)만 다룬다. 결국 전체 이미지를 다 보긴 하겠지만, 한 번에 한 패치만 처리한다는 것이 convolution의 중심 아이디어이다.

위의 예를 생각해보자. 전체 이미지의 크기는 3 x 3 x 1이고, 필터의 크기는 2 x 2 x 1이다. convolution은 필터를 사용해서 그 크기만큼만 보고, 필터를 움직이면서 결국 전체 이미지를 본다. 이 경우에는 stride가 1 x 1이므로
오른쪽으로 한 칸을 이동할 것이다. 그 이후 아래로 이동하고 오른쪽으로 이동해서 결국 전체를 다 본다.
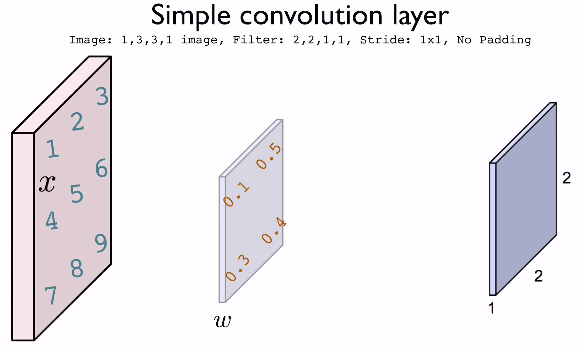
원본 이미지의 픽셀 값은 1,2,3,4,5,6,7,8,9가 있다. 우리는 필터의 크기에 맞춰서 이미 정의된 weight과 dot production 연산을 수행할 것이다. 처음에는 w · x = [0.1, 0.5, 0.3,0.4] · [1, 2, 4, 5]가 되어 각 위치마다 곱해서 더한다.
0.1 + 1 + 1.2 + 2 = 4.3의 결과를 얻을 수 있다. 그래서 최종값의 0,0인덱스의 값은 4.3이 된다. w · x의 값은 w의 전치 행렬과 x를 곱한 것과 같으므로 더 쉽게 연산할 수 있다.

padding을 적용한 예도 생각해보자. 주로 0을 가장자리에 에워싸는 zero padding을 사용하고, 이 경우에는 feature map의 크기가 3 x 3가 된다.

이렇게 padding의 사이즈가 다르면 feature map의 사이즈도 달라진다.

padding뿐만 아니라 stride도 여러 경우가 가능하다. stride가 1이라면 한 칸씩 이동했지만 만약 더 크다면 더 넓은 폭으로 이동 가능하다.

깊이가 있는 convolution layer도 생각해보자. RGB 색이 있다면 원본 이미지가 32 x 32 x 3의 정보가 있다고 생각할 수 있겠고, 필터에도 그만큼의 깊이를 주어서 5 x 5 x 3으로 설정하면 된다.

이 경우에는 필터가 5 x 5 x 3이므로 75번의 dot 곱셈이 이루어질 것이다.

이 경우에는 stride가 1이라고 했으므로 최종 activation map의 크기는 28 x 28일 것이다.

서로 다른 여러 개의 필터를 적용하는 것도 물론 가능하고 그에 따라서 activation map도 여러 개가 낭ㄹ 것이다.

우리가 몇 개의 필터를 사용할지가 activation map의 depth를 결정하게 될 것이다.

필터를 6개 사용해서 6 x 28 x 28의 결과를 얻은 뒤 10개의 서로 다른 필터를 사용해서 10 x 24 x 24의 결과를 얻는 등을 계속 반복한다.

또한 우리는 pooling(풀링) 또는 subsampling layer이라고 불리는 것을 각각의 convolution layer에 적용할 수도 있다.
convolution layer에 의해 만들어진 정보를 다시 사용하려고 하는 것이다.
위의 예에서는 max pooling이 사용됐고 2 x 2 크기의 필터를 사용하므로 첫번째 slice에서는 6이 가장 크고, 두번째 slice에서는 8이 가장 크므로 이런 식으로 가장 큰 값을 적는다. stride가 2라고 했으므로 2칸 이동한 것이다.
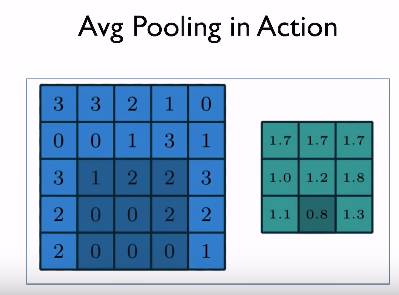
위에서 설명한 max pooling 이외에도 각각의 window의 평균을 구하는 average pooling도 있다.

Fully connected와 locally connected의 차이를 알아보도록 하겠다. Fully connected는 주어진 이미지의 모든 정보를 읽어서 우리의 신경망의 입력으로 넣는 것이고, CNN에서 사용되는 locally connected는 가중치를 모두 공유해서 쓰면서, 조그만 필터 사이즈로 각각 처리해서 따로따로 처리하는 것이다. 이렇게 locally connected를 사용할 경우에는 이미지를 다루기 flexible한다는 특징이 있다.

간단한 CNN 모델의 예를 살펴보겠다. MNIST 손글씨 데이터를 입력으로 받아서 2개의 convolution layer을 통과하고, 하나의 fully-connected layer을 마지막으로 통과한다. 이 경우에는 색이 하나이므로 in_channels가 1이고 결과로는 0부터 9 사이의 숫자이므로 out_channels에 10을 지정한다. maxpooling에서는 한 번에 몇 개를 보고 싶은지 지정한다.
fully-connected layer에는 softmax classifier에서 했던 것처럼 하나의 linear function을 사용한다.
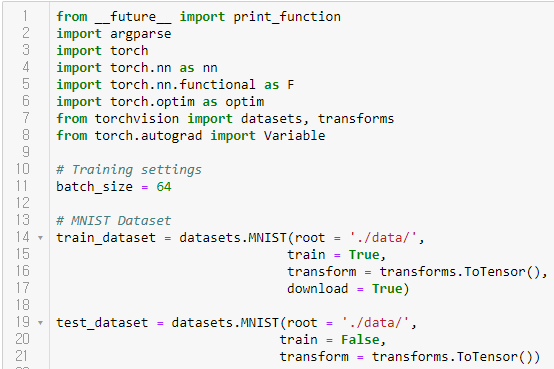



최종 코드는 위와 같다. 이전 예에서는 97%의 정확도를 얻었으나 이번에는 98%의 정확도를 얻었다.

결과적으로 loss가 점점 줄어드는 것을 볼 수 있다.

좀 더 깊은 네트워크를 한 번 구현해보는 것을 해보자.
다음 시간에는 advanced CNN을 알아보도록 하겠다.
'AI > PyTorchZeroToAll by Sung Kim' 카테고리의 다른 글
| [PyTorchZeroToAll] 11. Advanced CNN (0) | 2020.01.28 |
|---|---|
| [PyTorchZeroToAll] 9. Softmax Classifier (0) | 2020.01.27 |
| [PyTorchZeroToAll] 8. PyTorch DataLoader (0) | 2020.01.27 |
| [PyTorchZeroToAll] 7. Wide and Deep (0) | 2020.01.27 |
| [PyTorchZeroToAll] 6. Logistic Regression (0) | 2020.01.23 |



