저번 시간에는 데이터 마이닝이 무엇인지, 왜 필요한지에 대해 배웠다.
이번 시간에는 데이터 마이닝들이 수행하는 작업들에 대해 배워보도록 하겠다.
● Classification (Predictive)
- 분류는 지도학습에 해당한다.
- 분류하는 모델을 찾아야하는데, input으로 들어가는 attribute가 있고, output으로 나오는 attribute는
class attribute라고 한다.
- 분류한 뒤 그 결과가 맞는지 틀리는지는 일정한 시간이 지난 다음에 알 수 있는 경우가 있다. 예를 들어, 신용카드
회사에 고객이 정보를 신청하면 자신의 인적사항을 적으면 보통, 우수, 불량 고객인지 처음에 정하는데 정말
그런지는 한 달 뒤 정도에 알 수 있다.
- training set이라는 기록들의 모음이 주어지는데, 이것은 모델을 만드는 데 사용되는 데이터로, 정답이 주어지기 때문에
classification은 supervised learning이다.
→ class attribute라는 답을 미리 알고 있고, 모델이 예측한 calss attribute가 다르면 같아지도록 model을
조정해야한다.
- record는 attribute들을 가지고 있고, 그 중 하나가 class attribute이다.
- 다른 attribute들을 입력으로 가지는 함수인 모델을 만들고, class attribute를 출력으로 낸다.
- 이전에 보지 못한 record는 최대한 정확하게 class가 정해져야한다.
→ test set은 모델의 정확도를 결정하기 위해 사용된다. 보통 주어진 데이터셋은 training dataset과 test dataset으로
나뉘고, training set은 모델을 구축하기 위해 사용되고, test set은 그 모델을 검증하기 위해 사용된다.

위는 training dataset과 test dataset의 한 예인데, training dataset은 cheat이라는 class attribute가 주어지고, test dataset에는 빈칸으로 비어있어서, 우리가 예측해야함을 알 수 있다.
* Classification 사용
① Direct Marketing
- 목적 : 새로운 핸드폰 제품을 살 것 같은 사람들만 타겟으로 함으로써 우편을 보내는 비용을 줄인다.
* 방법
- 이전에 소개된 비슷한 제품에 대한 데이터들을 모은다.
- 우리는 어떤 고객들이 구매를 결정하는지 알고, 이 '산다(buy)', '안 산다(don't buy)'가 class attribute가 된다.
- 이러한 모든 고객들로부터 인류통계학, 생활 패턴 등의 관련된 정보를 얻는다.
- 이러한 정보들을 입력 attribute로 하여 classifier 모델을 훈련시킨다.
② Fraud Detection
- 목적 : 신용카드 거래 내역에서 부정 경우들을 예측한다.
* 방법
- 신용카드 거래 내역과 그 신용카드 주인의 정보들(언제, 무엇을, 얼마나 자주 구매하는지 등)을 attribute로 사용한다.
- 이전의 거래 내역을 부정 거래와 적절한 거래로 label한다. 이것이 class attribute가 된다.
- 모델을 거래에 대한 class로 훈련시킨다.
- 이 모델을 신용카드 거래 내역을 살펴봄으로써 사기를 detect하는 데 쓴다.
③ Customer Attrition / Churn
- 고객들의 감원 / 이탈 예측
→ 월마트같은 대형 소매점에서 고객이 어떤 결정을 할 것인지
- 목적 : 고객이 경쟁사로 이동할 것인지 아닌지를 예측한다.
* 방법
- 과거와 현재의 고객들의 거래 내역을 살펴보고 attribute를 뽑아낸다.
→ 예: 얼마나 자주 고객이 전화하는지, 어디에 전화하는지, 언제 가장 자주 전화하는지, 그 사람의 재정 상태,
결혼 여부 등
- 고객을 loyal, disloyal로 구분한다.
- loyalty를 class attribute로 하여 model을 훈련시킨다.
④ Sky Survey Cataloging
- 앞까지는 상업적인 목적으로 데이터마이닝을 이용했다면 이 예시는 과학적인 목적으로 데이터마이닝을 이용한다.
- 목적 : 천문에서는 별과 행성이 어마어마하게 많아서 분류가 필요한데, 하늘에서의 별이나 은하를 분류하고, 특히
잘 안 보이는 흐릿한 것들을 망원경 이미지로 구분한다.
* 방법
- 이미지를 부분부분 나눈다.
- 이미지에서 각 물체마다 40개 정도로 attribute를 추출한다.
● Clustering (Descriptive)
- Unsupervisesd Learning
- 여러 데이터 점들의 집합이 주어지면, attribute들이 각각 있고, 그들 중에서 유사도를 측정하고 cluster(군집)을 찾는다.
→ 하나의 군집에서의 데이터 점들은 서로 아주 유사하다.
→ 다른 군집에 있는 점들은 서로 덜 유사하다.
- 유사도 측정 방법
→ Euclidean Distance : 속성들이 연속적일 때 사용하는 직선 거리이다.
→ 문제에 따라 다른 방법이 쓰일 수도 있다.

- 위와 같이 거리가 가까운 것들을 모아서 같은 색으로 군집화했다.
- 여기에서는 x, y, z로 3개의 축이 있는데 각각 다른 attribute를 의미한다.
* Clustering 사용
① Market Segmentation
- 목적 : 시장을 분할하여 서로 유사한 고객들끼리 clustering함.
* 방법
- 고객들의 지리적, 생활 패턴에 기반한 서로 다른 속성들을 모은다.
- 비슷한 고객들에 대해 군집화를 한다.
- 고객들의 구매 패턴을 관찰함으로써 군집화 유사도를 측정하여 같은 군집에 둘지, 다른 군집에 둘지 결정한다.
② Document Clustering
- 목적 : 중요한 단어들에 기반하여 서로와 비슷한 문서들을 찾는다.
* 방법
- 각 문서들에서 자주 나타나는 단어들을 찾는다
- 유사도를 측정하여 군집화한다.
- 정보 검색 분야에서 새로운 문서를 연관시키거나 문서들을 군집화하기 위해 단어를 찾는 데에 사용된다.
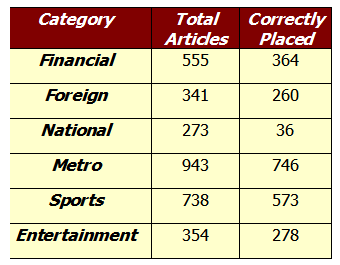
- 위의 예시는 Los Angeles Times의 3204개의 글들에서 유사한 단어들이 몇 번 나오는지 센 것이다.
③ Stock Data
- Big Data의 대부분이 금융 데이터이다.
- 금융 데이터가 바로 돈이기 때문에 그것을 잘 분석해서 유의미한 패턴을 잘 알아보아야한다.
- 같은 날에 자주 동시에 발생하는 사건이 있다면 유사한 것이므로 군집으로 묶는다.
- 그래서 up class, down class로 나누어서 30일 뒤에 주식이 상승할 것인지 아닌지를 예측한다.

● Association Rule Discovery (Descriptive)
- 연관 규칙
→ 예: 장바구니 분석
- 장바구니 안에 있는 어떤 물건과 다른 물건이 동시에 나오는 정도를 파악해서 연관짓는다.
- dependency rule을 만들어낸다.

- 위의 예시는 고객들이 동시에 산 물품들의 목록이다.
* Association Rule Discovery 사용
① Marketing and Sales Promotion
- 발견된 dependency rule이 'bagels를 사면 potato chips도 산다'라고 해보자.
- 감자칩은 결과 → 그것의 판매를 촉진시키기 위해 무엇을 해야할지 알아내는 데 쓰일 수 있다.
- 베이글은 조건 → 만약 해당 상점이 베이글을 팔지 안흔다면 어떤 상품들이 영향을 받을지 알아보는 데 쓰일 수 있다.
- 베이글 옆에 감자칩을 진열하는 등의 방법을 쓸 수 있다.
② Supermarket shelf management (진열대 관리)
- 목적 : 충분히 많은 고객들로부터 동시에 구매되는 물건들을 알아낸다.
* 방법
- 바코드 스캐너에서의 정보로 물건들 사이의 dependency를 알아낸다.
- 예: 만약 고객이 기저귀와 우유를 같이 산다면, 맥주도 살 가능성이 높다.
→ 그러므로 기저귀 옆에 맥주를 진열한다.
③ Inventory Management (재고 관리)
- 목적 : 가전제품 수리 회사의 고객이 물건 수리를 어떻게 맡길지를 예측해서 부품들을 미리 준비해놓는다.
* 방법
- 다른 고객 위치에서의 이전의 수리 내역을 보고 장비와 부품들을 알아낸 다음, 그로 인해 발생하는 패턴을 관측한다.
● Sequential Pattern Discovery (Descriptive)
- 시간적으로 떨어져있는 객체들에서 연속적인 dependency rule을 찾는다.
- 예 : 시간적으로 떨어져있는 구매 내역에서 구매 성향을 찾아라.
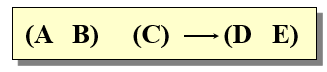
- 아래와 같이 계산하여 패턴을 찾는다.

● Regression (Predictive)
- input이 들어가면 output이 연속 값으로 나오는 형태이다.
- 주어진 연속된 입력에 따라 선형 또는 비선형 모델을 만들어서 출력을 예측한다
- 통계학과 신경망 분야에서 많이 연구되고 있다.
- 예:
① 광고 비용에 따른 신제품 판매 실적 예측
② 온도, 습도, 기압 등에 따른 바람의 속도 예측
③ 주식 시장에서 time series 예측
● Deviation Detection (Predictive)
- outlier detection이라고도 불린다.
- 대다수의 데이터와 다른 특별한 데이터를 찾는다.
- 평범한 행동들과 표준편차가 큰 것을 탐지한다.
- 신용카드 사기 검출, 네트워크 침투 검출에 쓰인다.
● Challenges of Data Mining
① Scalability
- 데이터 마이닝 알고리즘에서 입력 크기에 따라서 걸리는 시간이 기하급수적으로 늘어나면 이 모델은 못 쓴다.
- 대부분 빅 데이터를 쓰기 때문에 데이터 크기가 커져도 실행시간이 선형적으로 커져야한다.
② Dimensionality
- 데이터가 워낙 많으니 attribute들도 많아서 다차원의 저주 현상이 일어날 수 있다.
- 불필요한 attribute들을 제거하고 여러 가지 기법으로 attribute를 줄여서 차원 축소한다.
③ Complex and Heterogeneous Data
- text data, image data, voice data 등 데이터의 종류가 여러가지일 수 있다.
④ Data Quality
- 좋은 질의 데이터면 좋은 예측 결과가 나오고, 나쁜 질의 데이터면 나쁜 예측 결과가 나온다.
⑤ Data Ownership and Distribution
⑥ Privacy Preservation
⑦ Streaming Data
- 데이터가 실시간으로 들어오면 알고리즘이 달라질 수 있다.
다음 시간에는 구체적으로 데이터 마이닝을 하는 법에 대해 알아보도록 하겠다.
'CS > Data Mining' 카테고리의 다른 글
| [DataMining] Deep Learning (1) | 2020.05.03 |
|---|---|
| [DataMining] AI & Machine Learning (0) | 2020.05.03 |
| [DataMining] 2-2. Data Preprocessing (0) | 2020.04.30 |
| [DataMining] 1-1 . Introduction to Data Mining (0) | 2020.04.27 |



