
이번 시간에는 이미지 처리에 많이 사용되는 CNN에 대해 알아보도록 하겠다.
CNN은 1960년대에 신경과학자인 데이비드 휴벨(David Hubel)과 토르스텐 비젤(Torsten Wiesel)이 시각을 담당하는 신경세포를 연구하다가 서로 비슷한 이미지들이 뇌의 특정 부위를 지속적으로 자극하며 서로 다른 이미지는 다른 부위를 자극한다는 사실을 발견하여 발명되었다. 이미지의 각 부분에 뇌의 서로 다른 부분이 반응하여 전체 이미지를 인식하고, 이미지의 특징을 추출하여 우리 뇌가 인식한다는 것이다.
CNN은 Convolutional Neural Network의 줄임말로서, 합성곱 신경망이라고도 한다. 이미지나 비디오같은 영상 인식에 특화된 설계로, 병렬 처리가 쉬워서 대규모 서비스에 적용할 수 있고, 최근에는 이미지뿐만 아니라 자연어 처리와 추천 시스템에 응용되기도 한다.
※ 5.1 CNN 기초
● 5.1.1 컴퓨터가 보는 이미지
컴퓨터는 이미지의 픽셀값을 가로, 세로로 늘여놓은 행렬로 표현할 수 있다. 인공신경망은 다양한 형태의 입력에 적용되기가 힘들기 때문에 조금만 입력에 차이가 있어도 예측률이 급격히 떨어진다. 그렇기 때문에 pytorch의 transforms 도구를 사용하여 학습 데이터를 다양하게 변형한 다음 훈련하여 모델이 다양한 상황에도 적응할 수 있게 해야한다.
● 5.1.2 컨볼루션
사람이 이미지를 볼 때 배경, 질감, 움직임 등의 특징을 바로 잡아내는 것처럼 컨볼루션도 계층적으로 인식할 수 있도록 단계마다 이미지의 특징을 추출하는 것을 목적으로 한다. 각각 채도, 윤곽선 검출 등의 역할을 하는 필터를 따로 두고 각각 수행해서 이미지를 인식하는 것이고, 필터를 적용할 때 이미지 왼쪽 위에서 오른쪽 밑까지 밀어가며 곱하고 더하는 것을 컨볼루션(convolution)이라고 한다.
필터들을 하나하나 설계하면 다양한 이미지에 모두 적용되고, 사람의 실력에 좌우되며, 크고 복잡한 이미지에는 너무 많은 필터들이 필요로하기 때문에 비효율적이다. 그래서 CNN은 이미지를 추출하는 필터를 스스로 학습하는 것을 목표로 한다.
● 5.1.3 CNN 모델
CNN 모델은 컨볼루션 계층(convolution layer), 풀링 계층(pooling layer), 특징들을 모아 최종 분류하는 일반적인 인공 신경망 계층으로 구성된다. 컨볼루션 계층은 이미지의 특징을 추출하고, 풀링 계층은 필터를 거친 여러 특징 중 가장 중요한 특징 하나를 골라낸다. 이 과정에서 덜 중요한 특징을 버리기 때문에 더 작은 차원의 이미지를 얻을 수 있다.
컨볼루션 연산은 매우 작은 단위인 필터(filter), 커널(kernel)로 이미지를 보고, 보통 3 x 3, 5 x 5가 쓰인다. 몇 칸씩 움직이면서 볼지를 스트라이드(stride)로 정한다. stride가 클수록 출력되는 텐서의 크기가 작아지고, 이 결과를 특징 맵(feature map)이라고 한다. 컨볼루션 계층마다 여러 특징 맵이 만들어지고, 다음 단계인 풀링(pooling) 계층으로 넘어간다. 특징 맵의 크기가 너무 크면 학습이 어렵고 과적합의 위험이 증가한다. 위에서 언급했듯이, 풀링은 앞 계층에서 추출한 특징을 값 하나로 추려내서 특징 맵의 크기를 줄이고, 중요한 특징을 강조한다. 필터가 지나갈 때마다 픽셀을 묶어서 평균이나 최댓값을 가져오게 된다.
※ 5.2 CNN 모델 구현하기
이번에 구현할 CNN 모델의 구조는 아래와 같다.
컨볼루션 → 풀링 →컨볼루션 → 드롭아웃 → 풀링 → 신경망 → 드롭아웃 → 신경망

여러 라이브러리를 임포트한다.

USE_CUDA는 계산을 가속해주는 CUDA를 쓸 수 있는지 확인해주고, DEVICE는 USE_CUDA의 결과에 따라 데이터를 CUDA(GPU) 혹은 CPU로 보내도록 가리키는 역할을 한다.
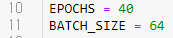
에폭과 배치 사이즈를 정한다.

학습용과 테스트용 데이터셋을 불러온다. transform을 이용한 전처리는 파이토치 텐서화와 정규화(normalization)만 한다. 커널 크기는 5 x 5, 컨볼루션 계층은 2개로 정의할 것이다.

Net이라는 클래스를 정의한다. 여기서 nn.Conv2d를 사용하는데, 첫번째 파라미터는 in_channels로 입력 채널 수를 지정하고, 두번째 파라미터는 out_channels로 출력 채널 수를 지정한다. 우리가 사용할 데이터는 흑백 데이터이므로 색상 채널이 하나이고, 위의 코드에 따르면 첫 컨볼루션 계층에서 10개의 특징 맵을 생성하고, 두번째 컨볼루션 계층에서 10개의 특징 맵을 받아서 20개의 특징 맵을 만든다. kernel_size는 각 컨볼루션 계층의 커널(필터) 크기를 지정할 수 있게 해준다. 꼭 정사각형이 아니여도 된다는 점을 기억하자.

드롭아웃 인스턴스를 만든다. 과적합을 방지하기 위해 쓰인다.

그 후 일반 신경망을 거치는데, 첫번째 계층에서는 320을 입력받아 50을 출력하고, 두번째 계층에서는 50을 입력받아 10개(0~9까지의 10개이므로)를 출력한다. 각 계층의 출력 크기는 계층이 진행될수록 작아지도록 임의로 정해도 된다.

forward에서는 입력을 받아 컨볼루션 계층을 지나고 풀링 계층을 거치는 것을 두 개의 컨볼루션 계층에 반복한다.
F.max_pool2d() 함수의 두번째 입력은 커널 크기이고, 드롭아웃과 같이 학습 파라미터가 없으므로 취향에 따라 F.max_pool2d() 같은 함수형을 사용하거나 nn.MaxPool2d와 같이 일반 모듈을 사용할 수도 있다.
view() 함수는 2차원의 특징 맵을 바로 입력으로 넣을 수 없으므로 1차원으로 펴주는 역할을 한다. 첫번째 입력 -1은 남는 차원 모두를 뜻하고, 두번째 320은 x가 가진 원소의 개수를 뜻한다.
그 다음에는 이렇게 추출한 특징들을 입력으로 받아서 분류한다. 첫번째 계층은 ReLU 활성화 함수를 거치고, 과적합을 방지하기 위해 드롭아웃을 사용한다.

방금 만든 CNN 모델의 인스턴스와 최적화 함수를 만든다.

모델을 train 모드로 놓은 후, 데이터셋에서 배치를 가져와 모델에서 출력값을 뽑고, F.cross_entropy() 오차 함수를 이용하여 모델 출력값과 정답인 target값 사이의 오차값을 계산한다. backpropagation을 실행해주는 loss.backward() 함수를 통해 기울기를 계산하고, 최적화 함수인 optimizer.step()으로 구한 기울기값을 사용해 모델의 학습 파라미터를 갱신한다.

성능을 평가한다.




전체 코드는 위와 같다.


CNN을 이용하니 위와 같이 정확도가 거의 99%로 올라간 것을 볼 수 있다.
※ 5.3 ResNet으로 컬러 데이터셋에 적용하기
지금까지 흑백 데이터만 다뤄봤으니 더 복잡한 컬러 데이터셋을 이용해보도록 하겠다.
● 5.3.1 ResNet 소개
ResNet(Residual network) 모델은 CNN을 응용한 모델이다. ResNet은 이미지 천만 장을 학습하여 이미지 15만 장으로 인식률을 겨루는 유명한 이미지넷(ImageNet) 대회에서 2015년에 우승한 모델인만큼 성능이 좋다. 신경망이 깊어질수록 오히려 성능이 나빠지는 Vanishing Gradients 문제 등을 해결하며 사람보다 더 나은 성능을 보였다.
구조는 컨볼루션층의 출력에 2개 전 계층의 입력을 더해서 특징이 유실되지 않게 한다.
● 5.3.2 CIFAR - 10 데이터셋
CIFAR - 10 데이터셋은 32 x 32 크기의 이미지 6만 개를 포함하고 있으며, 자동차, 새, 고양이, 사슴 등 10가지 분류가 존재하며 컬러라는 점에서 MNIST 데이터셋과 차이가 있다. 컬러 이미지의 픽셀값은 여러 가지 채널로 구성되는데, 여기서 채널(channel)은 이미지의 색상 구성, 빨강(R), 초록(G), 파랑(B)이 있다. 그렇기 때문에 32 x 32 x 3 = 3,072개가 존재하는 셈이다. 해당 이미지를 불러오는 방법은 다음과 같다.

앞에서 사용한 MNIST dataset과 달리 CIFAR-10 데이터셋을 불러온다. overfit을 방지하기 위해 RandomCrop과 RandomHorizontalFlip 등의 노이즈를 추가한다.
● 5.3.3 CNN을 깊게 쌓는 방법
인공 신경망에서 층을 많이 하면 점점 최초 입력 이미지에 대한 정보가 소실되기 때문에 학습 성능이 무조건 좋아지지는 않다. 그렇기 때문에 ResNet은 네트워크를 작은 블록인 Residual 블록으로 나누는데, Residual 블록의 출력에 입력이었던 x를 더함으로써 모델을 훨씬 깊게 설계할 수 있다. 입력과 출력의 차이를 따로 학습하는 것이 더 나은 결과를 보인다.
신경망을 깊게 하는 것의 목적은 문제를 더 작은 단위로 분해하여 학습 효율을 높이는 것인데 신호의 강도가 점점 줄어드는 것이 문제이므로 ResNet은 입력 데이터를 몇 계층씩 건너뛰어 출력에 더함으로써 이 현상을 완화해준다. Residual 블록을 반복적으로 쌓은 것 뿐이라서 생각보다 복잡하지는 않다. 이전에 사용했던 Conv2d와 Linear이 속해 있었던 nn.Module 클래스를 이용하여 모듈 위에 또 다른 모듈을 쌓아올릴 수 있다.

Residual 블록을 BasicBlock이라는 새로운 파이토치 모듈로 정의해서 사용하겠다. nn.BatchNorm2d라는 새로운 계층에서는 배치 정규화(batch regularization)을 수행하는데, 학습률을 너무 높게 잡았을 때 기울기가 소실되거나 발산하는 현상을 예방하여 학습 과정을 안정화하는 것이다. 학습 중 각 계층에 들어가는 입력을 평균과 분산으로 정규화함으로써 학습을 효율적으로 만들어주고, overfitting을 막는 드롭아웃과 같은 효과를 낸다. 단지 차이점은 드롭아웃이 데이터 일부를 배제하여 간접적으로 과적합을 막는 것이고, 배치 정규화는 신경망 내부 데이터에 직접 영향을 준다는 것이다.
Resnet은 두 번째 블록부터 in_planes를 받아서 self.bn2 계층의 출력 크기와 같은 planes와 더해주는 self.shortcut 모듈을 정의한다.

데이터의 흐름을 나타내는 forward는 다음과 같다. 입력이 들어오면 컨볼루션, 배치 정규화, 활성화 함수를 거치고, 다시 처음 입력을 self.shortcut을 거쳐서 크기를 같게 하고 활성화 함수를 거친 값에 더하고 그것을 ReLU 활성화 함수를 통과시켜 최종 출력을 만든다.

ResNet 클래스에서는 이미지를 받아서 컨볼루션과 배치정규화 층을 거친 후 여러 개의 BasicBlock 층, 평균 풀링, 신경망을 거쳐서 예측을 출력한다. self.make_layer() 함수는 파이토치의 nn.Sequential 도구로 여러 BasicBlock을 모듈 하나로 묶는 역할을 한다. 이 함수가 반환한 layer 객체는 컨볼루션 계층처럼 nn.Module로 다룰 수 있다.
self.in_plains 변수는 self._make_layers() 함수에서 각 층을 만들 때 전 층의 채널 출력값을 기록하는 데 씅니다. layer1 층이 16개 채널을 입력받으므로 16으로 초기화해준 것이다.
self.conv1 층은 3 x 3의 필터로 이미지의 RGB 3색을 16개의 채널로 만든다. 각 층을 지나면서 16 x 32 x 32, 32 x 16 x 16, 32 x 16 x 16, 64 x 8 x 8크기의 텐서를 가지게 된다. 끝에는 평균 풀링을 사용하여 텐서의 원소의 개수를 64개로 만들고 그만큼 입력을 받아서 10개마다 예측값을 낸다.

self._make_layer 함수에서는 self.in_planes 채널 개수로부터 직접 입력받은 인수인 planes 채널 개수만큼을 출력하는 BasicBlock을 생성한다.

ResNet에서의 데이터의 흐름은 입력이 들어오면 컨볼루션, 배치 정규화, 활성화 함수를 차례대로 통과한 뒤 BasicBlock 층을 갖는 layer1, layer2, layer3를 통과한다. 각 층은 2개의 Residual 블록을 갖고 있고, 각 값에 평균 풀링을 하고 마지막 계층을 거쳐서 분류 결과를 출력할 수 있다.

모델을 사용해보자. 학습률 감소(learning rate decay) 기법을 사용해서 학습이 진행하면서 최적화 함수의 학습률을 점점 낮춰서 더 정교하게 최적화하도록 한다. 파이토치의 optim.lr_scheduler.StepLR 도구로 간단하게 할 수 있고, 이 때 Scheduler는 이폭마다 호출되며 step_size를 50으로 지정해주어 50번 호출할 때 학습률에 0.1(gamma값)을 곱해서 0.1로 시작하면 0.01로 마지막에 줄어든다. 마지막으로 model을 출력하면 처음부터 끝까지 모든 계층이 어떻게 생겼는지 볼 수 있다.



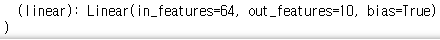
이렇게 계층이 생긴 것을 알 수 있다.

학습은 이전과 비슷하지만 달라진 점은 scheduler.step() 함수로 학습률을 조금 낮춰주는 단계가 추가되었다.






전체 코드는 위와 같다.


결과는 위와 같다. 정확도가 91% 정도가 나오는데 CIFAR-10이 성능을 충분히 올리기에 다소 작은 데이터셋이기 때문에 그렇다. 더 큰 데이터셋을 사용하여 학습 데이터를 늘리면 오차가 작아진다.
'AI > 펭귄브로의 3분 딥러닝 파이토치맛' 카테고리의 다른 글
| [3분 딥러닝] 4. 패션 아이템을 구분하는 DNN (0) | 2020.01.28 |
|---|---|
| [3분 딥러닝] 3. 파이토치로 구현하는 ANN (0) | 2020.01.21 |
| [3분 딥러닝] 1. 딥러닝과 파이토치 (0) | 2020.01.21 |


