저번 시간에 이어서 Fashion MINIST 데이터셋 안의 패션 아이템들을 구분하는 데 사용되는 DNN에 대해서 알아보도록 하겠다.
※ 4.1 Fashion MNIST 데이터셋 알아보기
딥러닝에서는 모델만큼이나 데이터셋이 중요한데, 데이터셋은 우리가 풀고자 하는 문제를 정의하는 것이기 때문이다. 저번 시간에 다뤘던 MNIST 손글씨 데이터와 달리 Fashion MNIST 데이터셋은 숫자를 인식하는 것에서 더 넘어서서 패션 아이템들을 구분할 수 있다.
Fashion MNIST는 28 x 28 픽셀의 70,000개의 흑백 이미지로, 신발, 드레스, 가방 등 10개의 카테고리로 존재한다.
원래는 이런 데이터를 받으면 데이터를 가공하고 파이프라인을 직접 만들어야하는데, 파이토치의 토치비전이 자동으로 내려받고 학습 데이터를 나누는 일까지 해준다. 앞으로 자주 쓰일 토치비전의 모듈을 꼭 기억해두자.
⊙ torch.utils.data
: 데이터셋의 표준을 정의하고 데이터셋을 불러오고 자르는 데 쓰인다. 파이토치 모델을 학습시키기 위한 데이터셋의 표준을 torch.utils.data.Dataset에 정의한다. Dataset 모듈을 상속하는 파생 클래스는 학습에 필요한 데이터를 로딩해주는 torch.utils.data.DataLoader 인스턴스의 입력으로 사용 가능하다.
⊙ torchvision.datasets
: torch.utils.data.Dataset을 상속하는 이미지 데이터셋의 모음이다. 패션 아이템 데이터셋이 들어있다.
⊙ torchvision.transforms
: 이미지 데이터셋에 쓸 수 있는 여러 가지 변환 필터를 담고 있는 모듈로, 텐서로 변환, 크기 조절(resize), 크롭crop)으로 이미지 수정, 밝기(brightness), 대비(contrast) 조절 등으로 쓰인다.
⊙ torchvision.utils
: 이미지 데이터를 저장하고 시각화하는 도구가 들어있는 모듈이다.
본격적으로 데이터를 분석해보자.

필요한 모듈들을 임포트 한 뒤 이미지를 텐서로 바꿔보자. torchvision의 transforms는 입력을 바꿔준다. 여기서는 ToTensor로 텐서로 바꿨지만, Resize()로 이미지 크기를 조정하고, Normalize()로 정규화하는 등 다양한 기능들이 존재한다. Compose 안에 다른 기능들도 넣으면 순서대로 수행된다.

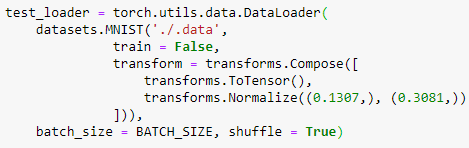
FashionMNIST 데이터셋을 가져오기 위해서 torchvision의 dataset 패키지는 데이터셋을 내려받고, Compose로 만들어 둔 이미지 변환 설정을 적용할 수 있다. download = True는 현재 root로 지정한 폴더에 데이터셋이 존재하는지 확인하고 없으면 자동으로 저장한다. 학습용 트레이닝셋은 train = True로, 성능 평가용 테스트셋은 train = False로 구분한다.
torchvision.datasets로 생성된 객체는 파이토치 내부 클래스 'torch.utils.data.Dataset'을 상속하므로 파이토치의 'DataLoader', 데이터셋을 로딩하는 클래스에 넣어서 바로 사용 가능하다. 'DataLoader'은 데이터셋을 배치(batch)라는 작은 단위로 쪼개고 학습 시 반복문 안에서 데이터를 공급해주는 역할을 한다.

batch_size는 한 번에 몇 개씩 설정하는지 정하는데, 이 예시에서는 16이므로 반복마다 16개씩 이미지를 읽는다. 컴퓨터의 메모리 공간에 여유가 있으면 크게, 작으면 적게 하는 식이다. DataLoader에 데이터셋을 넣고 배치 크기를 지정해주어서 그만큼 읽는다.

배치를 한 개를 가져오는데, 배치 1개의 images와 labels에는 앞서 설정한 배치 크기만큼 각각 이미지 16개와 레이블 16개가 들어있게 된다.
torchvision의 utils_make_grid() 함수로 배치 안의 여러 이미지들을 모아서 하나의 이미지로 만들고, 이때 img는 파이토치 텐서이기 때문에 numpy() 함수로 matplotlib과 호환이 되는 numpy 행렬로 바꾼다. matplotlib이 인식하는 차원의 순서가 다르므로 np.transpose() 함수로 첫번째(0번째) 차원을 맨 뒤로 보낸다.
matplotlib을 plt로 해서 figure() 함수로 이미지가 들어갈 자리를 만들고, imshow()와 show()로 이미지를 확인한다.

이미지의 클래스는 위와 같이 10개이고, 이름 대신에 숫자 레이블로 주어진다. 위와 같이 딕셔너리를 활용하면 사람들이 시각화된 데이터를 확인하기 편하다.

데이터에서 labels의 영문 텍스트를 출력해보면

위와 같다. 이미지의 데이터는 가로, 세로, 색상으로 표현된 3차원 행렬로 표현되는데 이 경우에는 가로세로의 각각의 픽셀 수, 흑백이므로 색상값은 1로 나타낸다. 각 픽셀은 0부터 255까지를 가지고 Fashion MNIST는 28 x 28의 크기를 갖으므로 입력 x의 특징값은 28 x 28 x 1로, 784개를 가진다.


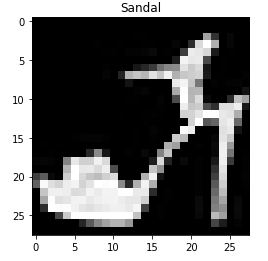



전체 코드와 결과는 위와 같다.
※ 4.2 인공 신경망으로 패션 아이템 분류하기
이제는 패션 아이템 이미지를 인식하여 레이블을 예측하는 기본적인 심층 인공 신경망(deep neural network, DNN)을 만들겠다.
● 4.2.1 환경 설정하기

nn 모듈은 파이토치, 인공 신경망 모델의 재료들을 담고 있고, optim 모듈은 최적화를 하고, functional은 nn 모듈의 함수 버전이다. transforms와 datasets는 torchvision의 데이터셋을 다루는 데 쓰인다.
torch.cuda.is_available() 함수는 CUDA를 이용할 수 있는지 알아보는데, CUDA용 pytorch와 CUDA가 준비되어있다면 True이고, 아니라면 False이다. CUDA를 지원하면 "cuda"를, 아니면 "cpu"를 torch.device에 설정하고, 여러 환경에서 돌아가는 코드를 공유할 때 잘 쓰인다. DEVICE라는 변수에 텐서와 가중치에 대한 연산을 CPU나 GPU 중 어디서 실행할지 결정할 때 쓰인다. CUDA용 파이터치를 설치하지 않아도 GPU를 가진 누구라도 코드를 돌릴 수 있다.
미니배치의 크기는 64로 해서 여러 개의 배치로 잘라서 쓸 수 있고, epoch는 학습 데이터 전체를 총 몇 번 볼건지를 결정한다.
● 4.2.2 이미지 분류 문제
이미지 분류(image classification)은 한 장의 이미지를 받아 이 이미지가 어느 클래스(레이블)에 속하는지 알려주는 문제이다. 여러 서비스에서 이미지 기반 검색, 추천, 광고 등에 사용된다.
● 4.2.3 이미지 분류를 위한 인공 신경망 구현
입력 x와 레이블 y를 받아서 학습한 다음, 새로운 x가 왔을 때 어떤 패션 아이템인지를 예측할 것이다. 레이어가 3개인 3층 인공 신경망을 구현해보도록 하겠다.

생성자에 우리 모델의 가중치 변수들이 들어가는 연산을 선언한다. nn.Linear 클래스는 선형 결합을 수행하는 객체를 만들고, 함수 fc1은 픽셀값 784개를 입력받아 가중치를 행렬곱하고 편향을 더해 값 256개를 출력한다. 이런 식으로 fc2와 fc3를 거쳐서 마지막에는 값 10개를 출력하고, 이 중 값이 가장 큰 클래스가 이 모델의 최종 예측값이 된다.
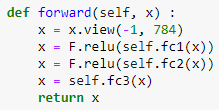
데이터의 흐름이 정의된다. 입력을 받으면 view() 함수로 1차원 행렬로 만든 뒤, fc1()과 fc2() 함수를 거치고 ReLU() 활성화 함수를 거친다. torch.nn.ReLU() 함수 이외에 가중치가 없는 연산은 torch.nn.functional에 있는 함수를 사용할 수도 있다. 또한, F.relu() 함수 대신 nn.ReLU 클래스를 사용하면 같은 기능을 하는 객체를 생성할 수도 있다.

to() 함수는 모델의 파라미터들을 지정한 장치의 메모리로 보내는 역할을 해서 연산을 어디서 수행할지 정할 수 있다. 만약 GPU를 사용할 것이라면 to("cuda")로 지정하여 GPU의 메모리로 보내면 되고, 지정하지 않으면 CPU에서 처리된다. 앞에서 미리 DEVICE를 지정했기 때문에 CUDA를 사용한다면 GPU로, 아니라면 CPU로 보낸다.
파이토치 내장 모듈인 optim.SGD로 최적화를 하는데, SGD(stochastic gradient descent)는 모델 최적화를 위한 확률적 경사하강법이다. model.parameters() 함수로 모델 내부의 정보를 넘겨주고, lr은 임의로 설정한 학습률로 0.01을 사용한다.

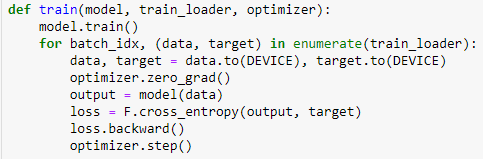
학습은 모델의 가중치를 변경하며 반복하고, train() 함수 안에서 해결되고, model, train_loader로 데이터를 공급하고, optimizer로 최적화를 하는 것이 전부이다. train()으로 모델을 학습 모드로 바꿔놓는데, 드롭아웃 등이 사용되므로 이렇게 해야한다. 모델에 들어가는 data의 모양(shape)은 [배치크기, 색, 높이, 넓이]로 되어있고, 이번 예시는 [64, 1, 28, 28]로 구성되어 있다. optimizer.zero_grad()는 반복 때마다 기울기를 다시 계산하고, 학습 데이터에 대한 모델의 예측값을 output에 저장한다.
output과 레이블인 target의 오차를 정한다. 클래스가 2개라면 이진 교차 엔트로피(binary cross entropy)를 사용하는데, 이 경우에는 클래스가 10개이므로 교차 엔트로피(cross entropy)를 사용한다. 이전에는 criterion() 함수에 nn.CrossEntropyLoss를 이용할 수도 있지만, 이번에는 torch.nn.functinal에 있는 cross_entropy() 함수를 사용할 것이다. loss는 미니배치 64개의 오차 평균인 하나의 숫자이다.
backward() 함수로 기울기(gradient)를 계산하고, optimizer.step() 함수는 그 기울기를 이용해 가중치를 수정한다.
※ 4.3 성능 측정하기
일반화(generalization)는 모든 데이터에 최적화하는 것을 말하고, 일반화 오류(generalization error)은 학습 데이터를 기반으로 한 모델이 학습하지 않은 데이터에 얼마나 적응하는지를 수치로 나타낸 것이다. 이 오류는 학습과 실제 성능의 괴리를 뜻하므로 작을수록 좋다.
보통은 데이터의 일부를 학습용 데이터로 나머지를 테스트셋으로 한다. 머신러닝 데이터셋은 학습(train), 검증(validation), 테스트(test) 3단계로 이루어져 있다. 학습용 데이터셋은 가중치를 조절하고, 검증용 데이터셋은 배치 크기와 모델 설계같은 하이퍼파라미터(hyperparameter)을 조절하는 데 쓰인다. 테스트용 데이터셋은 훈련 후 성능을 확인하는 데 쓰인다.

evaluate() 함수는 모델이 일반화를 얼마나 잘하는지 알아보고, 학습을 언제 멈추어야할지 알아보는 데 쓰인다. 모델 평가가 목적이므로 최적화는 하지 않고, model.eval()을 통해 모델을 평가 모드로 바꾼다. 그 이후 테스트 오차와 예측이 맞은 수를 담을 변수를 0으로 초기화한다.

평가 과정에서는 기울기를 계산하지 않고, torch.no_grad를 사용한다. 데이터를 DEVICE로 보내고, 모델의 예측값인 output을 받아온다.

테스트셋에서 얼마나 맞췄는지 다 더한다.

output.max 함수는 가장 큰 값과 그 값이 있는 자리인 인덱스를 출력한다. 우리는 인덱스를 더 중점적으로 볼 것이다. .eq() 함수를 사용해서 추출한 모델의 예측 패션 아이템과 레이블이 일치하는지를 알아보는데, 값이 일치하면 1, 아니면 0을 출력한다. 그래서 .sum()을 사용하면 맞은 것인 1들의 합이 구해지는 것이다. view_as() 함수는 target 텐서를 view_as() 함수 안에 들어가는 인수(pred)의 모양대로 다시 정렬한다.

이렇게 모델의 전체 데이터셋에 대한 오차와 맞힌 개수의 합을 구하면 이 평균을 구하고 100을 곱해서 정확도(accuracy)를 구한다.


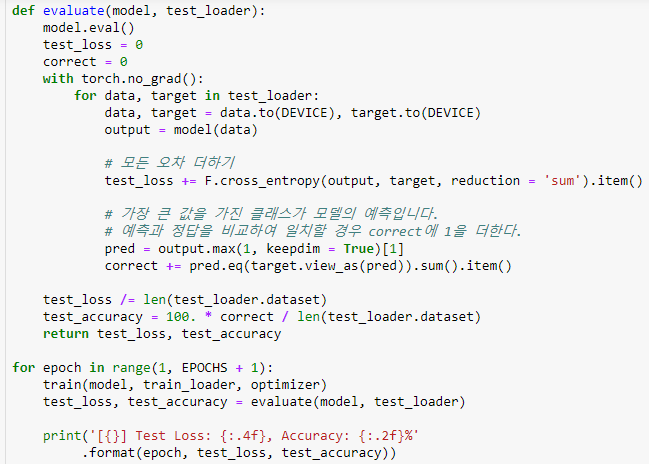

전체 코드와 결과는 위와 같다. 간단한 모델로 86.32%라는 정확도를 얻었으니 쓸 만하다.
※ 4.4 과적합과 드롭아웃
과적합(overfitting) 현상은 너무 학습 데이터에만 치중되어 유연성이 부족해지고, 그 결과 새로운 데이터에서는 성능이 잘 나오지 않는 것이다. 과소적합(underfitting) 현상은 학습 데이터도 제대로 학습되지 않은 경우이다. 우리는 과적합과 과소적합의 중간 단계인 일반화(generalization)의 상태를 원한다.
과적합을 막기 위해서 학습, 검증, 테스트셋으로 데이터셋을 나눌 수 있고, 조기 종료(early stopping)는 검증 데이터셋에 대한 성능이 나빠지기 시작하여 직전이 가장 적합한 모델이 될 때 모델을 저장하여 이용하는 것이다. 계속 학습하다보면 학습 오차가 0으로 수렴하고 검증 오차는 올라가게 되는데 이렇게 과적합하지 않기 위해 검증 오차가 올라가는 시점에 멈춰야한다.
● 4.4.1 데이터 늘리기
데이터가 최대한 많을수록 좋지만 데이터를 모으는 데 한계가 있으므로 이미 가진 데이터를 늘리는 것이(data augmentation) 사용된다. 이미지 데이터가 있다면 이미지 일부분을 자르기, 돌리기, 노이즈 더하기, 색상 변경 등 여러 방법들이 사용되고, 여기서는 오른쪽과 왼쪽을 뒤집는 가로 대칭이동 방법을 사용하겠다.

torchvision의 transforms 패키지로 데이터 조작을 쉽게 할 수 있다. transforms.Compose()와 함께 쓰인 transforms.RandomHorizontalFlip() 함수는 이미지를 무작위로 수평 뒤집기하고, 이렇게 학습 예제의 수를 2배로 늘릴 수 있다.
● 4.4.2 드롭아웃
데이터 조작 대신 모델에 직접 영향을 주어 과적합을 해결하는 방법이 드롭아웃(dropout)이다. 드롭아웃은 학습의 진행 과정에서 신경망의 일부를 사용하지 않는 방법인데, 검증과 테스트 단계에서는 모든 뉴런을 사용한다는 점에 주의하자. 이것은 학습에서 배재된 뉴런 외에 다른 뉴런들에 가중치를 분산시키고 개별 뉴런이 특징에 고정되는 현상을 방지하는 목적을 가지고 있다.

여기서는 드롭아웃 확률의 기본값을 0.2로 두었는데, 학습 시 20%의 뉴런을 사용하지 않겠다는 의미이다.

forward() 함수에 F.dropout() 가능을 추가하면 드롭아웃을 할 수 있다. F.dropout()은 가중치가 없어서 torch.nn.functional 패키지에서 바로 가져올 수 있고, nn.Dropout 클래스를 사용하는 것도 가능하다. nn.Dropout은 내부적으로 F.dropout() 함수를 쓰며, self.training 등 몇 가지 내부 변수를 자동으로 적용해주는 모듈이고, 이 둘의 차이는 같은 기능의 클래스를 쓰느냐 아니냐이다.
F.dropout() 함수는 학습 모드에서만 드롭아웃을 하고 평가에서는 모든 뉴런을 사용해야하기 때문에 모델의 모드에 따라 동작이 달라진다. 그래서 model.train()과 model.eval() 함수를 호출하여 모드를 바꿀 때마다 모델 내부의 self.training 변수값이 True나 False로 바뀐다.
이 예제 코드에서는 layer1, layer2를 지날 때 각각 드롭아웃을 한다. self.training은 신경망 층의 출력 x와 학습인지를 알려주는 역할을 하고, self.dropout_p는 드롭아웃 확률이다.

모델을 인스턴트화할 떄 드롭아웃 확률을 추가하면 마무리된다.






전체 코드와 결과이다. 점점 loss는 줄어들고, 정확도는 높아지는 것을 볼 수 있다.
데이터셋에 노이즈를 추가하거나 모델에 드롭아웃을 적용하면 최고 성능에 도달하는 데 걸리는 시간은 길어지므로, 이폭을 이전보다 더 늘려야 한다.
'AI > 펭귄브로의 3분 딥러닝 파이토치맛' 카테고리의 다른 글
| [3분 딥러닝] 5. 이미지 처리 능력이 탁월한 CNN (1) | 2020.01.28 |
|---|---|
| [3분 딥러닝] 3. 파이토치로 구현하는 ANN (0) | 2020.01.21 |
| [3분 딥러닝] 1. 딥러닝과 파이토치 (0) | 2020.01.21 |


